
本周三件事:基础概念补齐 · LLM-MAS 论文精读 · 申报书撰写。
方向逐渐聚焦到 credit assignment。
本周计划
- 补齐基础概念
- 继续阅读 LLM-MAS 论文
- 申报书撰写
一、基础概念
先是回头补了一些之前没有完全掌握的基础知识——在读多智能体 RL 的论文时,经常看到某些重复的概念但是一直没有理清它们之间的关系,遂系统过了一遍。
隐马尔可夫过程(HMM):本质上就是系统的真实状态不可观测,只能通过观测去推断。这个思路其实和之前 PSR 框架里 ProbeCommitEnv 的设计一脉相承——其中的 partner type 就是隐状态,ego agent 只能通过观测(混合了 u 和 nuisance 的信号)间接推断它。
GRPO 和 PPO 算法:这两个是目前 LLM RL 训练的核心算法,之前没做过系统对比。PPO 是经典的 Actor-Critic 架构,核心是用 clip 机制约束策略更新幅度,避免一步走太远导致训练崩溃,但需要额外训练一个 value network(critic)来估计 baseline。GRPO 是 DeepSeek 在训练 R1 时提出的,直接去掉了 critic 网络,改用同一个 prompt 下 K 个 rollout 的组内相对排名来估计 advantage。GRPO 的 advantage 是 group-level 的,在多智能体场景下,单个 agent 不知道自己到底贡献了多少,因此需要研究信用分配问题。这也是我们申报书中 CAD-GRPO 要解决的 credit contamination 问题的根源。
MARFT(Multi-Agent Reinforcement Fine-Tuning):多智能体场景下对 LLM 进行 RL 微调的基本范式。MARFT 提出了 Flex-MG formalism 来处理异步 LLM agent 的问题。标准的 MARL 假设所有 agent 同步决策,但在 LLM MAS 中,agent 有时候是按 turn 顺序交互的,因此把传统的 MARL 放到 LLM 场景下需要处理很多的 assumption mismatch。
SFT vs RLHF:之前一直搞混这两个概念,因为都是通过人的反馈来对机器进行优化微调。现在搞懂了——SFT 依赖固定标注数据集,RLHF 使用人类反馈来训练奖励模型。数据集的质量、代表性和结构直接影响模型的准确性、泛化能力和鲁棒性,因此 SFT 对数据集的要求极高。RLHF 则高度依赖于迭代式、可扩展的人类评估和偏好数据,先训一个 reward model 来捕获人类偏好,然后用 PPO/GRPO 这类策略优化方法去最大化这个 reward。这个近似化的 reward model 可能也是 reward hacking 的成因之一(猜测)。
二、阅读 LLM-MAS 论文
精读了 LangMARL 和 MHGPO 两篇。
2.1 LangMARL: Natural Language Multi-Agent Reinforcement Learning
核心 idea 是把传统 MARL 中的 Centralized Training Decentralized Execution (CTDE) 范式完整搬到自然语言空间——把 REINFORCE 算法里每一步数值计算都替换成了一次 LLM 调用,把网络参数 换成了 prompt text。它用 LLM 实现了四个组件:
- Language Policy Actor:每个 agent 维护一个文本形式的策略,执行去中心化的操作
- Centralized Language Critic:用一个 LLM 充当中心化评论家,分析完整轨迹后给每个 agent 生成文本形式的 credit assignment
- Language Policy Gradient Estimator:把 credit 信号转化为文本形式的"梯度方向"
- Language Policy Optimizer:整合多条轨迹的梯度方向,更新文本策略
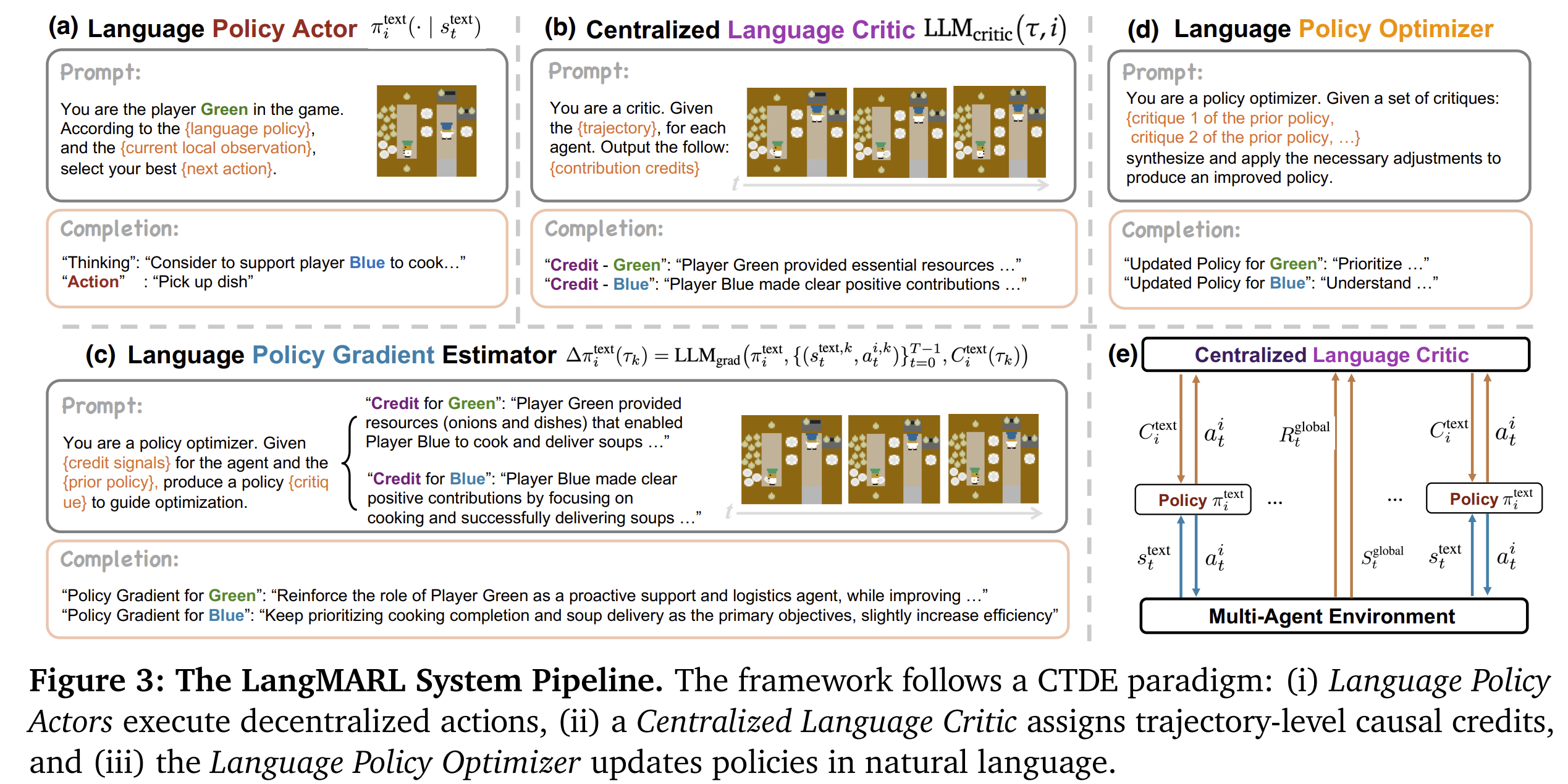
这篇论文做到了直接在语言空间做 credit assignment,不需要数值计算,也不需要修改模型参数。它的 Centralized Language Critic 如果真的和它所说的一样工作,那么确实能做到 per-agent 的 credit 分解,而且 critic 看到的是完整轨迹,理论上可以做因果推理。
但和我们目前研究的工作相比,首先它的信用分配质量完全依赖于 critic LLM 的推理能力。传统 MARL 里的 credit assignment(比如 COMA 的 counterfactual baseline)可以证明在某些条件下分解是无偏的、方差是减小的。但是 LangMARL 的这个 Language critic 本质上就是让 GPT 看一遍轨迹然后判断谁的贡献大——本质上还是一个黑盒过程。论文实验主要通过 ablation(去掉 credit assignment 后性能下降)来间接说明其有效性,因此值得推敲。
同时它的计算开销估计也不会低。虽然 LangMARL 不需要额外生成反事实轨迹(相比于 CCPO/C3),但它的每一步优化都需要多次 LLM 推理调用——critic 要对每条轨迹 × 每个 agent 生成 credit。这些推理开销在大规模训练中可并不 trivial。
2.2 MHGPO: Heterogeneous Group-Based Reinforcement Learning for LLM-based MAS
这篇貌似是一篇非常经典的论文,Dr.MAS 和 StrongerMAS 都引用了这篇(好像是,记不太清了)。它解决的是多智能体场景下 GRPO 的异构 agent 分组策略问题。在标准 GRPO 中,同一个 group 里的 rollout 需要共享相同的 prompt,但在多智能体系统中,不同 agent 有不同的角色和输入,天然就是异构的。
这篇论文提出了三种采样策略(之前师兄在分享的时候都讲过自己的理解了,我的理解也大差不差):
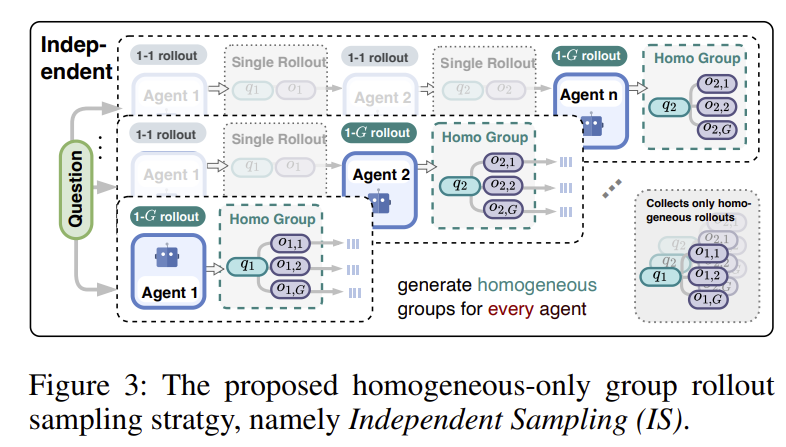
- Independent Sampling (IS):每个 agent 独立采 K 个 rollout,互相不耦合。相当于把每个 agent 当成一个独立的单智能体 GRPO 来训,agent 之间的交互关系被切断了。总 rollout 数 (n 个 agent,每个 G 条)。
-
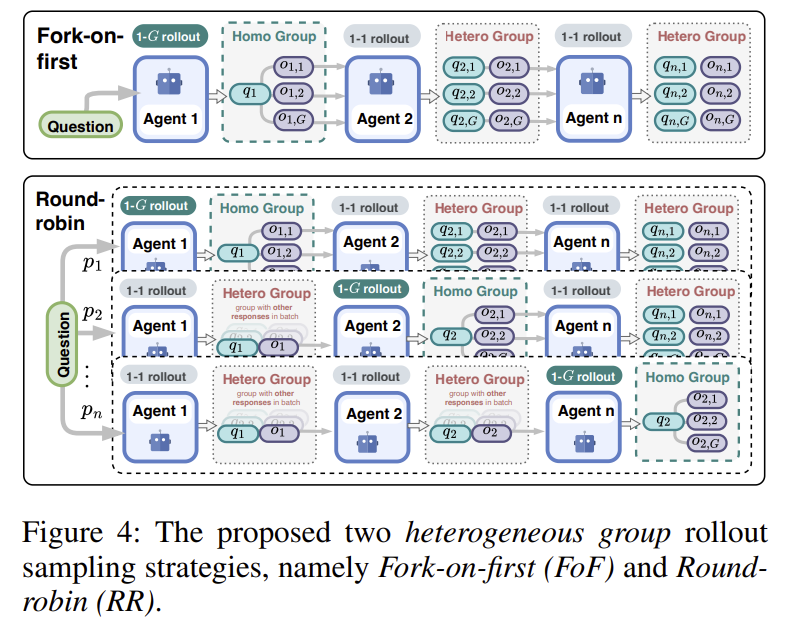
Fork-on-First (FoF):只在第一个 agent(entry agent)这里 fork 出 G 个分支,后续的 agent 每个分支只跑一次(一对一)。这样 entry agent 形成同构 group(相同输入 prompt,G 个不同输出),而下游 agent 的输入天然是异构的(因为上游给的输入就不同),形成异构 group。
-
Round-Robin (RR):按概率 随机选一个 agent 作为 fork point。在 fork point 之前的 agent 只跑一次,fork point 及之后的 agent 跑多次。相当于 IS 和 FoF 的折中。
训练使用的是一个三 agent 的 Multi-Agent Search System (MASS):Rewriter → Reranker → Answerer,在 HotpotQA 上实验。
在我看来,这三种采样策略的差异其实就是 fork 出多个分支的位置与时机不同。研究的就是在多 agent 的 pipeline 中,应该在哪个位置投入"多采样"的预算,才能既保证每个 agent 有足够的组内对比信号,又不让总的 rollout 开销爆炸。
novelty 主要在工程设计层面,理论贡献不算大。
三、申报书
最近一直在忙活的申报书,目前初步定为 credit assignment 方向——希望能将观察性因果推断引入 GRPO 框架,即利用 GRPO 已有采样轨迹中的自然变异,通过统计回归分解团队奖励,实现零额外开销(或极低开销,这个 claim 到时候可能需要改一下)的信用分解。
📄 申报书正文(课题全文)不在博客公开,仅保留上面这段概要说明。